
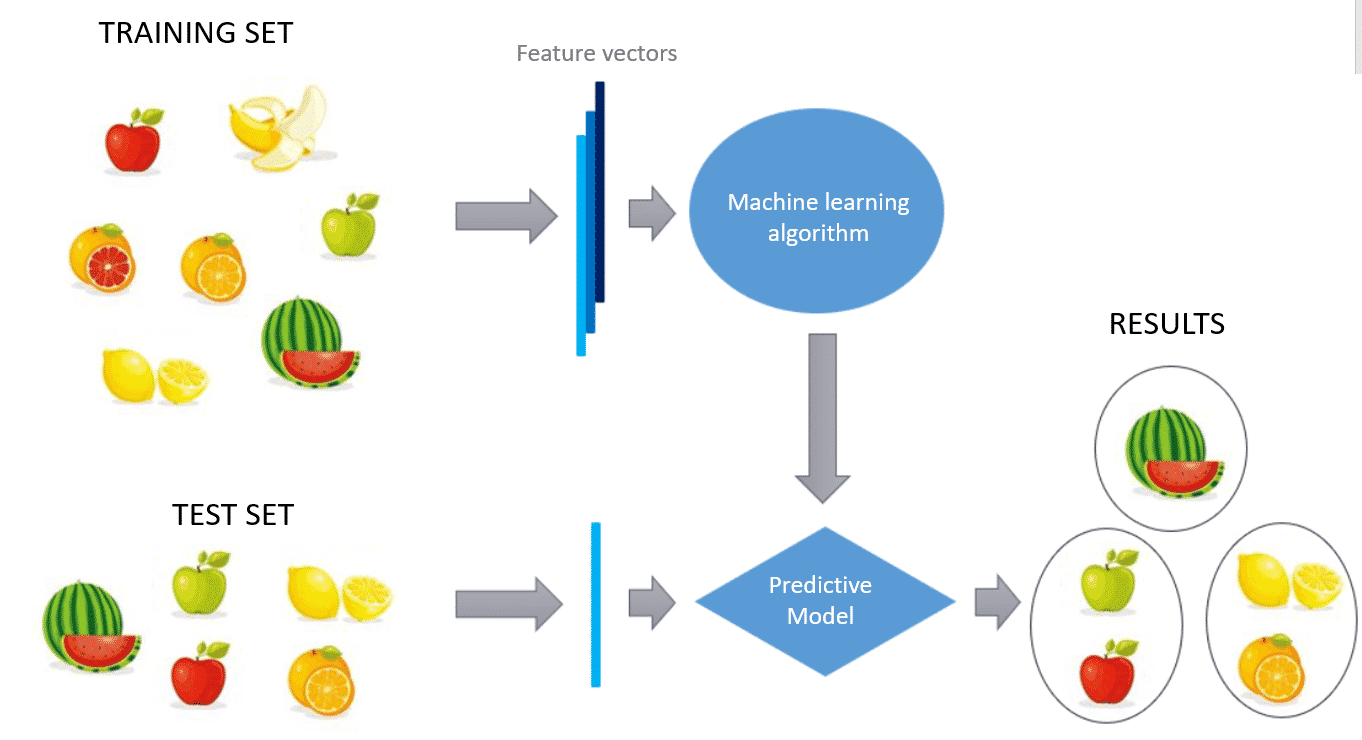
Unsupervised Learning: Mengungkap Pola Tersembunyi dalam Data Tanpa Label
Dalam era data yang berlimpah, kemampuan untuk mengekstrak informasi yang berharga dari data menjadi semakin krusial. Machine learning, sebagai cabang kecerdasan buatan, menawarkan berbagai teknik untuk menganalisis data dan membuat prediksi atau keputusan. Salah satu pendekatan yang paling menarik dan kuat adalah unsupervised learning. Berbeda dengan supervised learning yang memerlukan data berlabel untuk melatih model, unsupervised learning bekerja dengan data tanpa label, mencoba menemukan struktur, pola, dan hubungan yang tersembunyi di dalamnya.
Apa Itu Unsupervised Learning?
Unsupervised learning adalah jenis algoritma machine learning yang digunakan untuk menganalisis dan mengelompokkan data tanpa label. Data tanpa label adalah data yang tidak memiliki output atau target variabel yang telah ditentukan sebelumnya. Algoritma unsupervised learning mencoba menemukan pola, struktur, dan hubungan yang inheren dalam data, tanpa panduan eksplisit dari manusia.
Tujuan utama dari unsupervised learning adalah untuk:
- Menemukan struktur: Mengidentifikasi kelompok-kelompok data yang serupa (clustering).
- Mengurangi dimensi: Menyederhanakan data dengan mengurangi jumlah variabel sambil mempertahankan informasi penting (dimensionality reduction).
- Mendeteksi anomali: Mengidentifikasi titik data yang tidak biasa atau berbeda dari pola yang diharapkan (anomaly detection).
- Mempelajari representasi: Mengembangkan representasi data yang lebih ringkas dan bermakna untuk digunakan dalam tugas-tugas lain (feature learning).
Perbedaan dengan Supervised Learning
Perbedaan utama antara unsupervised learning dan supervised learning terletak pada keberadaan label dalam data pelatihan. Dalam supervised learning, algoritma dilatih menggunakan data yang memiliki label yang benar. Algoritma belajar untuk memprediksi label yang benar berdasarkan fitur-fitur input. Contoh supervised learning termasuk klasifikasi (memprediksi kategori) dan regresi (memprediksi nilai numerik).
Sebaliknya, unsupervised learning bekerja dengan data tanpa label. Algoritma harus menemukan pola dan struktur dalam data sendiri, tanpa panduan eksplisit. Hal ini membuat unsupervised learning lebih menantang, tetapi juga lebih fleksibel dan mampu mengungkap wawasan yang tidak terduga.
Jenis-Jenis Algoritma Unsupervised Learning
Beberapa jenis algoritma unsupervised learning yang paling umum meliputi:
Clustering:
- K-Means: Membagi data ke dalam k kelompok (cluster) berdasarkan jarak ke pusat cluster (centroid). Algoritma ini iteratif, terus memperbarui posisi centroid hingga konvergensi.
- Hierarchical Clustering: Membangun hierarki cluster, baik dengan menggabungkan cluster-cluster kecil secara bertahap (agglomerative) atau membagi cluster besar menjadi cluster-cluster yang lebih kecil (divisive).
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): Mengelompokkan titik-titik data yang berdekatan dengan kepadatan tinggi, menandai titik-titik yang berada di daerah dengan kepadatan rendah sebagai outlier.
Dimensionality Reduction:
- Principal Component Analysis (PCA): Mengubah data ke dalam set variabel baru yang tidak berkorelasi (principal components), yang diurutkan berdasarkan jumlah varians yang dijelaskan. Komponen utama pertama menjelaskan varians terbanyak, komponen utama kedua menjelaskan varians terbanyak berikutnya, dan seterusnya. Dengan memilih sejumlah kecil komponen utama, kita dapat mengurangi dimensi data sambil mempertahankan sebagian besar informasi penting.
- t-distributed Stochastic Neighbor Embedding (t-SNE): Teknik non-linear yang sangat baik untuk memvisualisasikan data berdimensi tinggi dalam ruang dua atau tiga dimensi. t-SNE mempertahankan struktur lokal data, sehingga titik-titik data yang berdekatan dalam ruang berdimensi tinggi juga akan berdekatan dalam ruang berdimensi rendah.
- Autoencoders: Jaringan saraf tiruan yang dilatih untuk merekonstruksi inputnya sendiri. Autoencoder terdiri dari dua bagian: encoder, yang mengubah input menjadi representasi berdimensi rendah (latent space), dan decoder, yang merekonstruksi input dari representasi latent space.
Anomaly Detection:
- Isolation Forest: Membangun pohon keputusan secara acak untuk mengisolasi anomali. Anomali cenderung memiliki jalur yang lebih pendek dalam pohon karena mereka lebih mudah diisolasi.
- One-Class SVM: Melatih model SVM untuk hanya mengenali data normal. Setiap titik data yang berada di luar batas yang ditentukan oleh model dianggap sebagai anomali.
- Local Outlier Factor (LOF): Menghitung skor outlier lokal untuk setiap titik data berdasarkan kepadatan tetangga di sekitarnya. Titik-titik data dengan skor LOF yang tinggi dianggap sebagai outlier.
Aplikasi Unsupervised Learning
Unsupervised learning memiliki berbagai aplikasi di berbagai bidang, termasuk:
- Segmentasi Pelanggan: Mengelompokkan pelanggan berdasarkan perilaku pembelian, demografi, atau preferensi untuk menargetkan kampanye pemasaran yang lebih efektif.
- Analisis Pasar: Mengidentifikasi tren dan pola dalam data penjualan untuk mengoptimalkan strategi penetapan harga dan promosi.
- Deteksi Penipuan: Mengidentifikasi transaksi yang mencurigakan atau tidak biasa dalam data keuangan.
- Pengenalan Gambar: Mengelompokkan gambar berdasarkan fitur visual mereka, seperti warna, tekstur, dan bentuk.
- Pemrosesan Bahasa Alami (NLP): Mengelompokkan dokumen teks berdasarkan topik atau tema mereka.
- Bioinformatika: Mengidentifikasi pola dalam data genetik atau protein untuk memahami penyakit dan mengembangkan obat-obatan baru.
- Keamanan Siber: Mendeteksi aktivitas jaringan yang mencurigakan atau anomali yang dapat mengindikasikan serangan siber.
- Rekomendasi Sistem: Memberikan rekomendasi yang dipersonalisasi kepada pengguna berdasarkan riwayat interaksi mereka dengan sistem.
- Analisis Sensor Data: Mengidentifikasi pola atau anomali dalam data sensor dari mesin industri atau perangkat IoT untuk pemeliharaan prediktif.
Keuntungan dan Kekurangan Unsupervised Learning
Keuntungan:
- Tidak memerlukan data berlabel: Mengurangi biaya dan upaya yang diperlukan untuk mengumpulkan dan melabeli data.
- Menemukan wawasan tersembunyi: Mampu mengungkap pola dan hubungan yang tidak terduga dalam data.
- Fleksibel dan adaptif: Dapat digunakan untuk berbagai jenis data dan tugas.
- Berguna untuk eksplorasi data: Membantu memahami struktur dan karakteristik data sebelum menerapkan teknik machine learning lainnya.
Kekurangan:
- Interpretasi hasil yang sulit: Hasil unsupervised learning seringkali sulit diinterpretasikan dan memerlukan pengetahuan domain yang mendalam.
- Evaluasi kinerja yang sulit: Tidak ada metrik evaluasi yang jelas seperti dalam supervised learning.
- Sensitif terhadap parameter: Kinerja algoritma unsupervised learning dapat sangat bergantung pada pemilihan parameter yang tepat.
- Membutuhkan preprocessing data yang cermat: Kualitas data sangat penting untuk keberhasilan unsupervised learning.
Kesimpulan
Unsupervised learning adalah alat yang ampuh untuk menganalisis data tanpa label dan mengungkap pola serta hubungan yang tersembunyi. Meskipun lebih menantang daripada supervised learning, unsupervised learning menawarkan fleksibilitas dan kemampuan untuk menemukan wawasan yang tidak terduga. Dengan pemahaman yang baik tentang berbagai jenis algoritma unsupervised learning dan aplikasi mereka, kita dapat memanfaatkan kekuatan data untuk memecahkan masalah kompleks dan membuat keputusan yang lebih baik. Seiring dengan terus berkembangnya bidang machine learning, unsupervised learning akan memainkan peran yang semakin penting dalam berbagai bidang, membuka peluang baru untuk inovasi dan penemuan.












